

$$ \begin{pmatrix} a_1 & a_2 \end{pmatrix} = \begin{pmatrix} sigmoid(z_1) & sigmoid(z_2) \end{pmatrix} $$
$$
sigmoid(t) = \frac{1}{1+e^{-t}}
$$

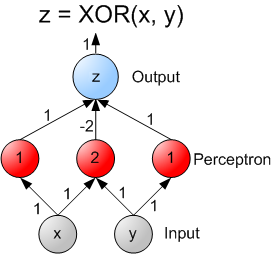

Gradient Descent
梯度下降

BackPropagation
反向传播算法




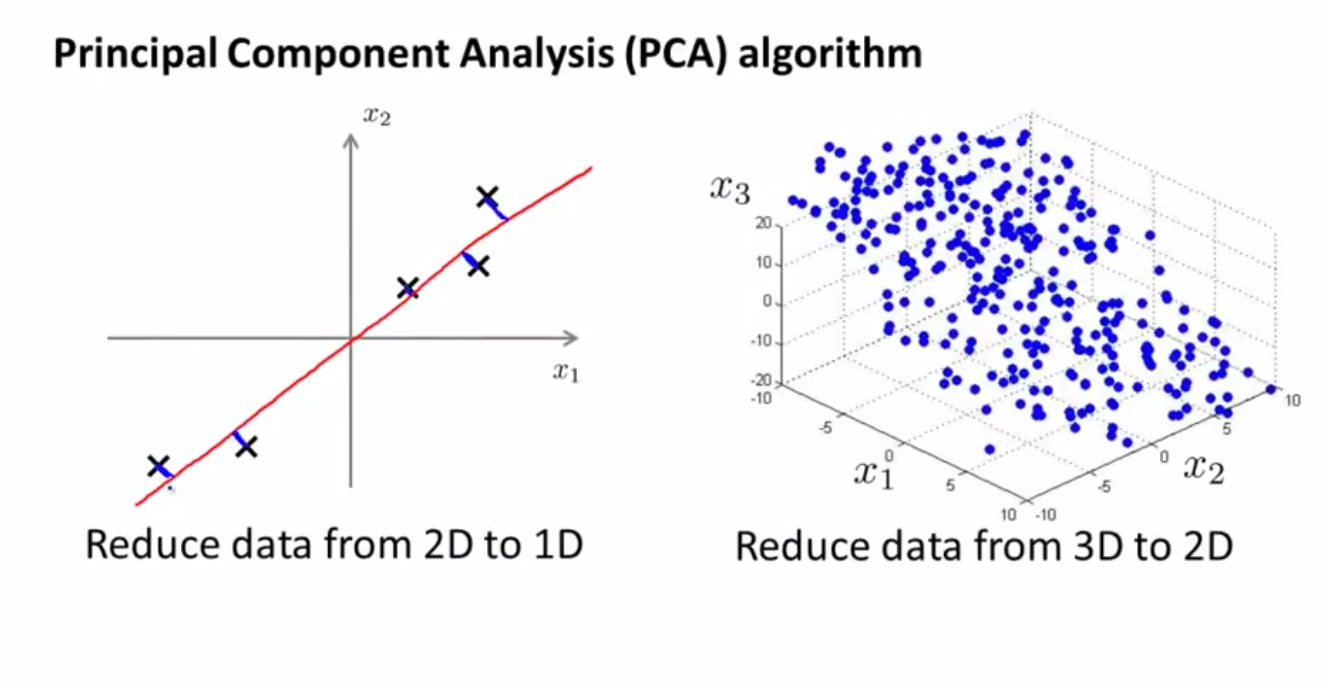
主成分分析
Principal Component Analysis (PCA)
自动编码器
AutoEncoder